![]()
假如说,如果你的老板给你的任务是一次又一次地访问竞争对手的网站,把对方商品的价格记录下来,而且要纯手工操作,恐怕你会想要把整个办公室都烧掉。
之所以现在网络爬虫的影响力如此巨大,就是因为网络爬虫可以被用于追踪客户的情绪和趋向、搜寻空缺的职位、监控房地产的交易,甚至是获取 UFC 的比赛结果。除此以外,还有很多意想不到的用途。
对于有这方面爱好的人来说,爬虫无疑是一个很好的工具。因此,我使用了 Scrapy 这个基于 Python 编写的开源网络爬虫框架。
鉴于我不太了解这个工具是否会对我的计算机造成伤害,我并没有将它搭建在我的主力机器上,而是搭建在了一台树莓派上面。
令人感到意外的是,Scrapy 在树莓派上面的性能并不差,或许这是 ARM 架构服务器的又一个成功例子?
我尝试 Google 了一下,但并没有得到令我满意的结果,仅仅找到了一篇相关的《Drupal 建站对比》。这篇文章的结论是,ARM 架构服务器性能比昂贵的 x86 架构服务器要更好。
从另一个角度来看,这种 web 服务可以看作是一个“被爬虫”服务,但和 Scrapy 对比起来,前者是基于 LAMP 技术栈,而后者则依赖于 Python,这就导致两者之间没有太多的可比性。
那我们该怎样做呢?只能在一些 VPS 上搭建服务来对比一下了。
什么是 ARM 架构处理器?
ARM 是目前世界上最流行的 CPU 架构。
但 ARM 架构处理器在很多人眼中的地位只是作为一个省钱又省电的选择,而不是跑在生产环境中的处理器的首选。
然而,诞生于英国剑桥的 ARM CPU,最初是用于极其昂贵的 Acorn Archimedes 计算机上的,这是当时世界上最强大的桌面计算机,甚至在很长一段时间内,它的运算速度甚至比最快的 386 还要快好几倍。
Acorn 公司和 Commodore、Atari 的理念类似,他们认为一家伟大的计算机公司就应该制造出伟大的计算机,让人感觉有点目光短浅。而比尔盖茨的想法则有所不同,他力图在更多不同种类和价格的 x86 机器上使用他的 DOS 系统。
拥有大量用户基数的平台会成为第三方开发者开发软件的平台,而软件资源丰富又会让你的计算机更受用户欢迎。
即使是苹果公司也几乎被打败。在 x86 芯片上投入大量的财力,最终,这些芯片被用于生产环境计算任务。
但 ARM 架构也并没有消失。基于 ARM 架构的芯片不仅运算速度快,同时也非常节能。因此诸如机顶盒、PDA、数码相机、MP3 播放器这些电子产品多数都会采用 ARM 架构的芯片,甚至在很多需要用电池或不配备大散热风扇的电子产品上,都可以见到 ARM 芯片的身影。
而 ARM 则脱离 Acorn 成为了一种特殊的商业模式,他们不生产实物芯片,仅仅是向芯片生产厂商出售相关的知识产权。
因此,这或多或少是 ARM 芯片被应用于如此之多的手机和平板电脑上的原因。当 Linux 被移植到这种架构的芯片上时,开源技术的大门就已经向它打开了,这才让我们今天得以在这些芯片上运行 web 爬虫程序。
服务器端的 ARM
诸如微软和 Cloudflare 这些大厂都在基础设施建设上花了重金,所以对于我们这些预算不高的用户来说,可以选择的余地并不多。
实际上,如果你的信用卡只够付每月数美元的 VPS 费用,一直以来只能考虑 Scaleway 这个高性价比的厂商。
但自从数个月前公有云巨头 AWS 推出了他们自研的 ARM 处理器 AWS Graviton 之后,选择似乎就丰富了一些。
我决定在其中选择一款 VPS 厂商,将它提供的 ARM 处理器和 x86 处理器作出对比。
深入了解
所以我们要对比的是什么指标呢?
Scaleway
Scaleway 自身的定位是“专为开发者设计”。我觉得这个定位很准确,对于开发和原型设计来说,Scaleway 提供的产品确实可以作为一个很好的沙盒环境。
Scaleway 提供了一个简洁的仪表盘页面,让用户可以快速地从主页进入 bash shell 界面。对于很多小企业、自由职业者或者技术顾问,如果想要运行 web 爬虫,这个产品毫无疑问是一个物美价廉的选择。
ARM 方面我们选择 ARM64-2GB 这一款服务器,每月只需要 3 欧元。它带有 4 个 Cavium ThunderX 核心,这是在 2014 年推出的第一款服务器级的 ARMv8 处理器。但现在看来它已经显得有点落后了,并逐渐被更新的 ThunderX2 取代。
x86 方面我们选择 1-S,每月的费用是 4 欧元。它拥有 2 个英特尔 Atom C3995 核心。英特尔的 Atom 系列处理器的特点是低功耗、单线程,最初是用在笔记本电脑上的,后来也被服务器所采用。
两者在处理器以外的条件都大致相同,都使用 2 GB 的内存、50 GB 的 SSD 存储以及 200 Mbit/s 的带宽。磁盘驱动器可能会有所不同,但由于我们运行的是 web 爬虫,基本都是在内存中完成操作,因此这方面的差异可以忽略不计。
为了避免我不能熟练使用包管理器的尴尬局面,两方的操作系统我都会选择使用 Debian 9。
Amazon Web Services(AWS)
当你还在注册 AWS 账号的时候,使用 Scaleway 的用户可能已经把提交信用卡信息、启动 VPS 实例、添加 sudo 用户、安装依赖包这一系列流程都完成了。AWS 的操作相对来说比较繁琐,甚至需要详细阅读手册才能知道你正在做什么。
当然这也是合理的,对于一些需求复杂或者特殊的企业用户,确实需要通过详细的配置来定制合适的使用方案。
我们所采用的 AWS Graviton 处理器是 AWS EC2(弹性计算云)的一部分,我会以按需实例的方式来运行,这也是最贵但最简捷的方式。AWS 同时也提供竞价实例,这样可以用较低的价格运行实例,但实例的运行时间并不固定。如果实例需要长时间持续运行,还可以选择预留实例。
看,AWS 就是这么复杂……
我们分别选择 a1.medium 和 t2.small 两种型号的实例进行对比,两者都带有 2GB 内存。这个时候问题来了,这里提到的 vCPU 又是什么?两种型号的不同之处就在于此。
对于 a1.medium 型号的实例,vCPU 是 AWS Graviton 芯片提供的单个计算核心。这个芯片由被亚马逊在 2015 收购的以色列厂商 Annapurna Labs 研发,是 AWS 独有的单线程 64 位 ARMv8 内核。它的按需价格为每小时 0.0255 美元。
而 t2.small 型号实例使用英特尔至强系列芯片,但我不确定具体是其中的哪一款。它每个核心有两个线程,但我们并不能用到整个核心,甚至整个线程。
我们能用到的只是“20% 的基准性能,可以使用 CPU 积分突破这个基准”。这可能有一定的原因,但我没有弄懂。它的按需价格是每小时 0.023 美元。
在镜像库中没有 Debian 发行版的镜像,因此我选择了 Ubuntu 18.04。
瘪四与大头蛋爬取 Moz 排行榜前 500 的网站
要测试这些 VPS 的 CPU 性能,就该使用爬虫了。一个方法是对几个网站在尽可能短的时间里发出尽可能多的请求,但这种操作不太礼貌,我的做法是只向大量网站发出少数几个请求。
为此,我编写了 beavis.py(瘪四)这个爬虫程序(致敬我最喜欢的物理学家和制片人 Mike Judge)。这个程序会将 Moz 上排行前 500 的网站都爬取 3 层的深度,并计算 “wood” 和 “ass” 这两个单词在 HTML 文件中出现的次数。(LCTT 译注:beavis(瘪四)和 butt-head(大头蛋) 都是 Mike Judge 的动画片《瘪四与大头蛋》中的角色)
但我实际爬取的网站可能不足 500 个,因为我需要遵循网站的 robot.txt 协定,另外还有些网站需要提交 javascript 请求,也不一定会计算在内。但这已经是一个足以让 CPU 保持繁忙的爬虫任务了。
Python 的全局解释器锁机制会让我的程序只能用到一个 CPU 线程。为了测试多线程的性能,我需要启动多个独立的爬虫程序进程。
因此我还编写了 butthead.py,尽管大头蛋很粗鲁,它也总是比瘪四要略胜一筹。
我将整个爬虫任务拆分为多个部分,这可能会对爬取到的链接数量有一点轻微的影响。但无论如何,每次爬取都会有所不同,我们要关注的是爬取了多少个页面,以及耗时多长。
在 ARM 服务器上安装 Scrapy
安装 Scrapy 的过程与芯片的不同架构没有太大的关系,都是安装 pip 和相关的依赖包之后,再使用 pip 来安装 Scrapy。
据我观察,在使用 ARM 的机器上使用 pip 安装 Scrapy 确实耗时要长一点,我估计是由于需要从源码编译为二进制文件。
在 Scrapy 安装结束后,就可以通过 shell 来查看它的工作状态了。
在 Scaleway 的 ARM 机器上,Scrapy 安装完成后会无法正常运行,这似乎和 service_identity 模块有关。这个现象也会在树莓派上出现,但在 AWS Graviton 上不会出现。
对于这个问题,可以用这个命令来解决:
sudo pip3 install service_identity --force --upgrade
接下来就可以开始对比了。
单线程爬虫
Scrapy 的官方文档建议将爬虫程序的 CPU 使用率控制在 80% 到 90% 之间,在真实操作中并不容易,尤其是对于我自己写的代码。根据我的观察,实际的 CPU 使用率变动情况是一开始非常繁忙,随后稍微下降,接着又再次升高。
在爬取任务的最后,也就是大部分目标网站都已经被爬取了的这个阶段,会持续数分钟的时间。这让人有点失望,因为在这个阶段当中,任务的运行时长只和网站的大小有比较直接的关系,并不能以之衡量 CPU 的性能。
所以这并不是一次严谨的基准测试,只是我通过自己写的爬虫程序来观察实际的现象。
下面我们来看看最终的结果。首先是 Scaleway 的机器:
| 机器种类 |
耗时 |
爬取页面数 |
每小时爬取页面数 |
每百万页面费用(欧元) |
| Scaleway ARM64-2GB |
108m 59.27s |
38,205 |
21,032.623 |
0.28527 |
| Scaleway 1-S |
97m 44.067s |
39,476 |
24,324.648 |
0.33011 |
我使用了 top 工具来查看爬虫程序运行期间的 CPU 使用率。在任务刚开始的时候,两者的 CPU 使用率都达到了 100%,但 ThunderX 大部分时间都达到了 CPU 的极限,无法看出来 Atom 的性能会比 ThunderX 超出多少。
通过 top 工具,我还观察了它们的内存使用情况。随着爬取任务的进行,ARM 机器的内存使用率最终达到了 14.7%,而 x86 则最终是 15%。
从运行日志还可以看出来,当 CPU 使用率到达极限时,会有大量的超时页面产生,最终导致页面丢失。这也是合理出现的现象,因为 CPU 过于繁忙会无法完整地记录所有爬取到的页面。
如果仅仅是为了对比爬虫的速度,页面丢失并不是什么大问题。但在实际中,业务成果和爬虫数据的质量是息息相关的,因此必须为 CPU 留出一些用量,以防出现这种现象。
再来看看 AWS 这边:
| 机器种类 |
耗时 |
爬取页面数 |
每小时爬取页面数 |
每百万页面费用(美元) |
| a1.medium |
100m 39.900s |
41,294 |
24,612.725 |
1.03605 |
| t2.small |
78m 53.171s |
41,200 |
31,336.286 |
0.73397 |
为了方便比较,对于在 AWS 上跑的爬虫,我记录的指标和 Scaleway 上一致,但似乎没有达到预期的效果。这里我没有使用 top,而是使用了 AWS 提供的控制台来监控 CPU 的使用情况,从监控结果来看,我的爬虫程序并没有完全用到这两款服务器所提供的所有性能。
a1.medium 型号的机器尤为如此,在任务开始阶段,它的 CPU 使用率达到了峰值 45%,但随后一直在 20% 到 30% 之间。
让我有点感到意外的是,这个程序在 ARM 处理器上的运行速度相当慢,但却远未达到 Graviton CPU 能力的极限,而在 Intel Atom 处理器上则可以在某些时候达到 CPU 能力的极限。它们运行的代码是完全相同的,处理器的不同架构可能导致了对代码的不同处理方式。
个中原因无论是由于处理器本身的特性,还是二进制文件的编译,又或者是两者皆有,对我来说都是一个黑盒般的存在。我认为,既然在 AWS 机器上没有达到 CPU 处理能力的极限,那么只有在 Scaleway 机器上跑出来的性能数据是可以作为参考的。
t2.small 型号的机器性能让人费解。CPU 利用率大概 20%,最高才达到 35%,是因为手册中说的“20% 的基准性能,可以使用 CPU 积分突破这个基准”吗?但在控制台中可以看到 CPU 积分并没有被消耗。
为了确认这一点,我安装了 stress 这个软件,然后运行了一段时间,这个时候发现居然可以把 CPU 使用率提高到 100% 了。
显然,我需要调整一下它们的配置文件。我将 CONCURRENT_REQUESTS 参数设置为 5000,将 REACTOR_THREADPOOL_MAXSIZE 参数设置为 120,将爬虫任务的负载调得更大。
| 机器种类 |
耗时 |
爬取页面数 |
每小时爬取页面数 |
每万页面费用(美元) |
| a1.medium |
46m 13.619s |
40,283 |
52,285.047 |
0.48771 |
| t2.small |
41m7.619s |
36,241 |
52,871.857 |
0.43501 |
| t2.small(无 CPU 积分) |
73m 8.133s |
34,298 |
28,137.8891 |
0.81740 |
a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升到了 100%,随后下降到 80% 并持续了 20 分钟,然后再次攀升到 96%,直到任务接近结束时再次下降。这大概就是我想要的效果了。
而 t2.small 型号机器在爬虫任务的前期就达到了 50%,并一直保持在这个水平直到任务接近结束。如果每个核心都有两个线程,那么 50% 的 CPU 使用率确实是单个线程可以达到的极限了。
现在我们看到它们的性能都差不多了。但至强处理器的线程持续跑满了 CPU,Graviton 处理器则只是有一段时间如此。可以认为 Graviton 略胜一筹。
然而,如果 CPU 积分耗尽了呢?这种情况下的对比可能更为公平。为了测试这种情况,我使用 stress 把所有的 CPU 积分用完,然后再次启动了爬虫任务。
在没有 CPU 积分的情况下,CPU 使用率在 27% 就到达极限不再上升了,同时又出现了丢失页面的现象。这么看来,它的性能比负载较低的时候更差。
多线程爬虫
将爬虫任务分散到不同的进程中,可以有效利用机器所提供的多个核心。
一开始,我将爬虫任务分布在 10 个不同的进程中并同时启动,结果发现比每个核心仅使用 1 个进程的时候还要慢。
经过尝试,我得到了一个比较好的方案。把爬虫任务分布在 10 个进程中,但每个核心只启动 1 个进程,在每个进程接近结束的时候,再从剩余的进程中选出 1 个进程启动起来。
如果还需要优化,还可以让运行时间越长的爬虫进程在启动顺序中排得越靠前,我也在尝试实现这个方法。
想要预估某个域名的页面量,一定程度上可以参考这个域名主页的链接数量。我用另一个程序来对这个数量进行了统计,然后按照降序排序。经过这样的预处理之后,只会额外增加 1 分钟左右的时间。
结果,爬虫运行的总耗时超过了两个小时!毕竟把链接最多的域名都堆在同一个进程中也存在一定的弊端。
针对这个问题,也可以通过调整各个进程爬取的域名数量来进行优化,又或者在排序之后再作一定的修改。不过这种优化可能有点复杂了。
因此,我还是用回了最初的方法,它的效果还是相当不错的:
| 机器种类 |
耗时 |
爬取页面数 |
每小时爬取页面数 |
每万页面费用(欧元) |
| Scaleway ARM64-2GB |
62m 10.078s |
36,158 |
34,897.0719 |
0.17193 |
| Scaleway 1-S |
60m 56.902s |
36,725 |
36,153.5529 |
0.22128 |
毕竟,使用多个核心能够大大加快爬虫的速度。
我认为,如果让一个经验丰富的程序员来优化的话,一定能够更好地利用所有的计算核心。但对于开箱即用的 Scrapy 来说,想要提高性能,使用更快的线程似乎比使用更多核心要简单得多。
从数量来看,Atom 处理器在更短的时间内爬取到了更多的页面。但如果从性价比角度来看,ThunderX 又是稍稍领先的。不过总的来说差距不大。
爬取结果分析
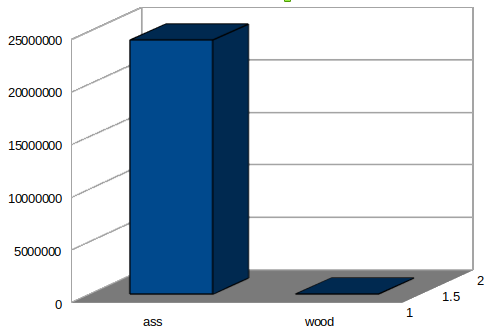
在爬取了 38205 个页面之后,我们可以统计到在这些页面中 “ass” 出现了 24170435 次,而 “wood” 出现了 54368 次。
![]()
“wood” 的出现次数不少,但和 “ass” 比起来简直微不足道。
结论
从上面的数据来看,对于性能而言,CPU 的架构并没有它们的问世时间重要,2018 年生产的 AWS Graviton 是单线程情况下性能最佳的。
你当然可以说按核心来比,Xeon 仍然赢了。但是,你不但需要计算美元的变化,甚至还要计算线程数。
另外在性能方面 2017 年生产的 Atom 轻松击败了 2014 年生产的 ThunderX,而 ThunderX 则在性价比方面占优。当然,如果你使用 AWS 的机器的话,还是使用 Graviton 吧。
总之,ARM 架构的硬件是可以用来运行爬虫程序的,而且在性能和费用方面也相当有竞争力。
而这种差异是否足以让你将整个技术架构迁移到 ARM 上?这就是另一回事了。当然,如果你已经是 AWS 用户,并且你的代码有很强的可移植性,那么不妨尝试一下 a1 型号的实例。
希望 ARM 设备在不久的将来能够在公有云上大放异彩。
源代码
这是我第一次使用 Python 和 Scrapy 来做一个项目,所以我的代码写得可能不是很好,例如代码中使用全局变量就有点力不从心。
不过我仍然会在下面开源我的代码。
要运行这些代码,需要预先安装 Scrapy,并且需要 Moz 上排名前 500 的网站的 csv 文件。如果要运行 butthead.py,还需要安装 psutil 这个库。
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from scrapy.crawler import CrawlerProcess
ass = 0
wood = 0
totalpages = 0
def getdomains():
moz500file = open('top500.domains.05.18.csv')
domains = []
moz500csv = moz500file.readlines()
del moz500csv[0]
for csvline in moz500csv:
leftquote = csvline.find('"')
rightquote = leftquote + csvline[leftquote + 1:].find('"')
domains.append(csvline[leftquote + 1:rightquote])
return domains
def getstartpages(domains):
startpages = []
for domain in domains:
startpages.append('http://' + domain)
return startpages
class AssWoodItem(scrapy.Item):
ass = scrapy.Field()
wood = scrapy.Field()
url = scrapy.Field()
class AssWoodPipeline(object):
def __init__(self):
self.asswoodstats = []
def process_item(self, item, spider):
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
def close_spider(self, spider):
asstally, woodtally = 0, 0
for asswoodcount in self.asswoodstats:
asstally += asswoodcount[1]
woodtally += asswoodcount[2]
global ass, wood, totalpages
ass = asstally
wood = woodtally
totalpages = len(self.asswoodstats)
class BeavisSpider(CrawlSpider):
name = "Beavis"
allowed_domains = getdomains()
start_urls = getstartpages(allowed_domains)
#start_urls = [ 'http://medium.com' ]
custom_settings = {
'DEPTH_LIMIT': 3,
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 1500,
'REACTOR_THREADPOOL_MAXSIZE': 60,
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
'LOG_LEVEL': 'INFO',
'RETRY_ENABLED': False,
'DOWNLOAD_TIMEOUT': 30,
'COOKIES_ENABLED': False,
'AJAXCRAWL_ENABLED': True
}
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
def parse_asswood(self, response):
if isinstance(response, scrapy.http.TextResponse):
item = AssWoodItem()
item['ass'] = response.text.casefold().count('ass')
item['wood'] = response.text.casefold().count('wood')
item['url'] = response.url
yield item
if __name__ == '__main__':
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
process.crawl(BeavisSpider)
process.start()
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
beavis.py
import scrapy, time, psutil
from scrapy.spiders import CrawlSpider, Rule, Spider
from scrapy.linkextractors import LinkExtractor
from scrapy.crawler import CrawlerProcess
from multiprocessing import Process, Queue, cpu_count
ass = 0
wood = 0
totalpages = 0
linkcounttuples =[]
def getdomains():
moz500file = open('top500.domains.05.18.csv')
domains = []
moz500csv = moz500file.readlines()
del moz500csv[0]
for csvline in moz500csv:
leftquote = csvline.find('"')
rightquote = leftquote + csvline[leftquote + 1:].find('"')
domains.append(csvline[leftquote + 1:rightquote])
return domains
def getstartpages(domains):
startpages = []
for domain in domains:
startpages.append('http://' + domain)
return startpages
class AssWoodItem(scrapy.Item):
ass = scrapy.Field()
wood = scrapy.Field()
url = scrapy.Field()
class AssWoodPipeline(object):
def __init__(self):
self.asswoodstats = []
def process_item(self, item, spider):
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
def close_spider(self, spider):
asstally, woodtally = 0, 0
for asswoodcount in self.asswoodstats:
asstally += asswoodcount[1]
woodtally += asswoodcount[2]
global ass, wood, totalpages
ass = asstally
wood = woodtally
totalpages = len(self.asswoodstats)
class ButtheadSpider(CrawlSpider):
name = "Butthead"
custom_settings = {
'DEPTH_LIMIT': 3,
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 250,
'REACTOR_THREADPOOL_MAXSIZE': 30,
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
'LOG_LEVEL': 'INFO',
'RETRY_ENABLED': False,
'DOWNLOAD_TIMEOUT': 30,
'COOKIES_ENABLED': False,
'AJAXCRAWL_ENABLED': True
}
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
def parse_asswood(self, response):
if isinstance(response, scrapy.http.TextResponse):
item = AssWoodItem()
item['ass'] = response.text.casefold().count('ass')
item['wood'] = response.text.casefold().count('wood')
item['url'] = response.url
yield item
def startButthead(domainslist, urlslist, asswoodqueue):
crawlprocess = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
crawlprocess.start()
asswoodqueue.put( (ass, wood, totalpages) )
if __name__ == '__main__':
asswoodqueue = Queue()
domains=getdomains()
startpages=getstartpages(domains)
processlist =[]
cores = cpu_count()
for i in range(10):
domainsublist = domains[i * 50![]() i + 1) * 50]
pagesublist = startpages[i * 50
i + 1) * 50]
pagesublist = startpages[i * 50![]() i + 1) * 50]
p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
processlist.append(p)
for i in range(cores):
processlist.start()
time.sleep(180)
i = cores
while i != 10:
time.sleep(60)
if psutil.cpu_percent() < 66.7:
processlist.start()
i += 1
for i in range(10):
processlist.join()
for i in range(10):
asswoodtuple = asswoodqueue.get()
ass += asswoodtuple[0]
wood += asswoodtuple[1]
totalpages += asswoodtuple[2]
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
i + 1) * 50]
p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
processlist.append(p)
for i in range(cores):
processlist.start()
time.sleep(180)
i = cores
while i != 10:
time.sleep(60)
if psutil.cpu_percent() < 66.7:
processlist.start()
i += 1
for i in range(10):
processlist.join()
for i in range(10):
asswoodtuple = asswoodqueue.get()
ass += asswoodtuple[0]
wood += asswoodtuple[1]
totalpages += asswoodtuple[2]
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
butthead.py
via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/
作者:James Mawson 选题:lujun9972 译者:HankChow 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出
![]()








 references” 窗口中,打开左窗格中的 &ldquo
references” 窗口中,打开左窗格中的 &ldquo














 org-projectile-open-project%20"mana")][mana]] [3/9]
org-projectile-open-project%20"mana")][mana]] [3/9]
 ROPERTIES:
:CATEGORY: mana
:END:
** DONE [[file:~/Development/mana/apps/blockchain/lib/blockchain/contract/create_contract.ex::insufficient_gas_before_homestead%20=][fix this check using evm.configuration]]
CLOSED: [2018-08-08 Ср 09:14]
[[https://github.com/ethereum/EIPs/blob/master/EIPS/eip-2.md][eip2]]:
If contract creation does not have enough gas to pay for the final gas fee for
adding the contract code to the state, the contract creation fails (i.e. goes out-of-gas)
rather than leaving an empty contract.
** DONE Upgrade Elixir to 1.7.
CLOSED: [2018-08-08 Ср 09:14]
** TODO [#A] Difficulty tests
** TODO [#C] Upgrage to OTP 21
** DONE [#A] EIP150
CLOSED: [2018-08-14 Вт 21:25]
*** DONE operation cost changes
CLOSED: [2018-08-08 Ср 20:31]
*** DONE 1/64th for a call and create
CLOSED: [2018-08-14 Вт 21:25]
** TODO [#C] Refactor interfaces
** TODO [#B] Caching for storage during execution
** TODO [#B] Removing old merkle trees
** TODO do not calculate cost twice
* [[elisp
ROPERTIES:
:CATEGORY: mana
:END:
** DONE [[file:~/Development/mana/apps/blockchain/lib/blockchain/contract/create_contract.ex::insufficient_gas_before_homestead%20=][fix this check using evm.configuration]]
CLOSED: [2018-08-08 Ср 09:14]
[[https://github.com/ethereum/EIPs/blob/master/EIPS/eip-2.md][eip2]]:
If contract creation does not have enough gas to pay for the final gas fee for
adding the contract code to the state, the contract creation fails (i.e. goes out-of-gas)
rather than leaving an empty contract.
** DONE Upgrade Elixir to 1.7.
CLOSED: [2018-08-08 Ср 09:14]
** TODO [#A] Difficulty tests
** TODO [#C] Upgrage to OTP 21
** DONE [#A] EIP150
CLOSED: [2018-08-14 Вт 21:25]
*** DONE operation cost changes
CLOSED: [2018-08-08 Ср 20:31]
*** DONE 1/64th for a call and create
CLOSED: [2018-08-14 Вт 21:25]
** TODO [#C] Refactor interfaces
** TODO [#B] Caching for storage during execution
** TODO [#B] Removing old merkle trees
** TODO do not calculate cost twice
* [[elisp










































![[LoliHouse] Princess-Session Orchestra - 15 [WebRip 1080p HEVC-10bit...](http://s2.loli.net/2025/04/09/QO618K72ytGZmDJ.webp)







